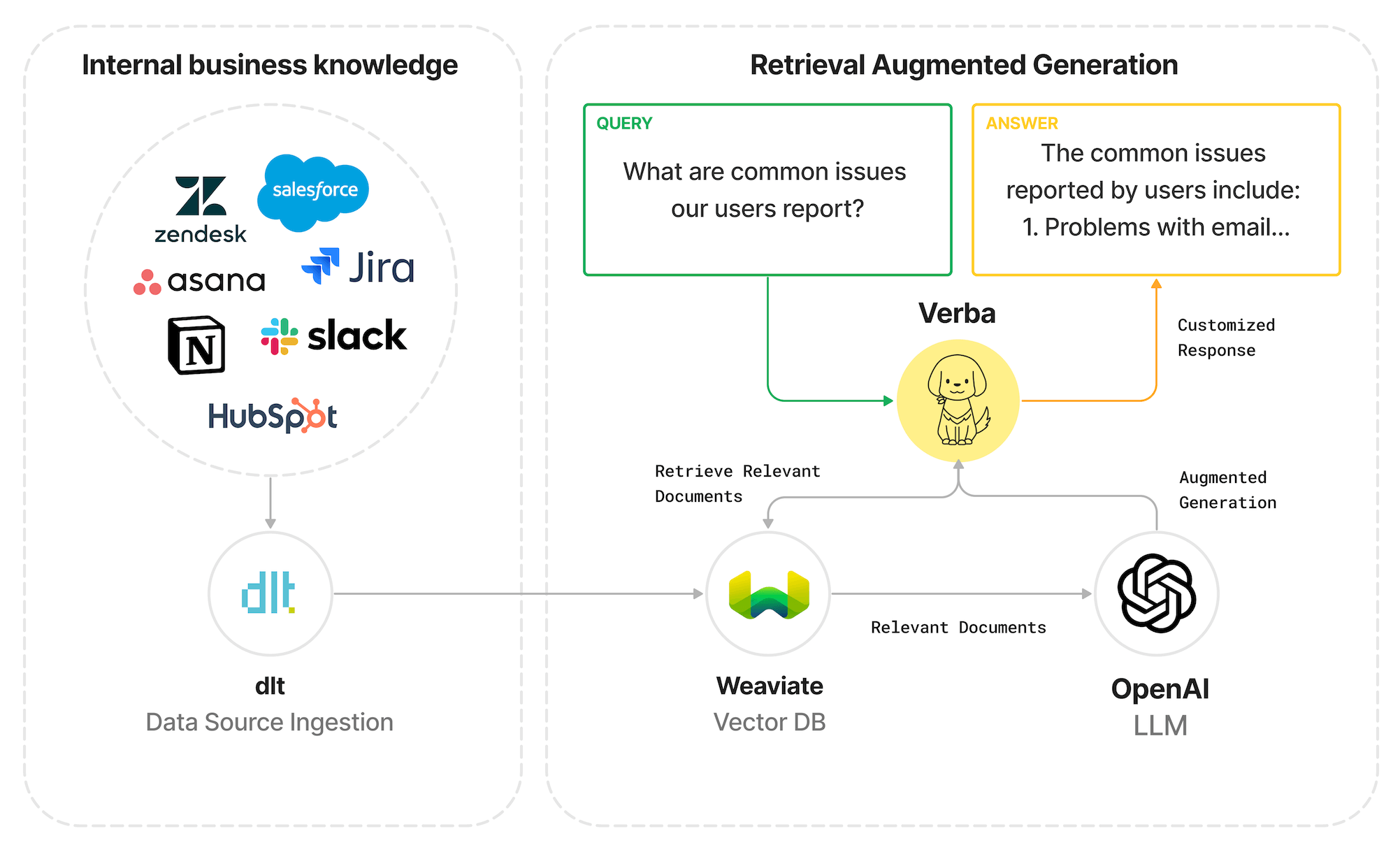
THE PROBLEM
There are two types of people: those who hoard thousands of unread emails in their inbox and those who open them immediately to avoid the ominous red notification. But one thing unites us all: everyone hates emails. The reasons are clear:
- They're often unnecessarily wordy, making them time-consuming.
- SPAM (obviously).
- They become black holes of lost communication because CC/BCC-ing people doesn't always work.
- Sometimes, there are just too many.
So, this post will explore a possible remedy to the whole email issue involving AI.
THE SOLUTION
Don't worry; it's nothing overly complex, but it does involve some cool tools that everyone could benefit from.
💡 In a nutshell, I created two flows (a main flow and a subflow) in Kestra :
- The main flow extracts email data from Gmail and loads it into BigQuery using
dlt, checks for new emails, and, if found, triggers the subflow for further processing.- The subflow utilizes OpenAI to summarize and analyze the sentiment of an email, loads the results into BigQuery, and then notifies about the details via Slack.
Just so you're aware:
Kestrais an open-source automation tool that makes both scheduled and event-driven workflows easy.dltis an open-source library that you can add to your Python scripts to load data from various and often messy data sources into well-structured, live datasets.
Wanna jump to the GitHub repo?
HOW IT WORKS
To lay it all out clearly: Everything's automated in Kestra, with hassle-free data loading thanks to dlt, and the analytical thinking handled by OpenAI. Here's a diagram to help you understand the general outline of the entire process.
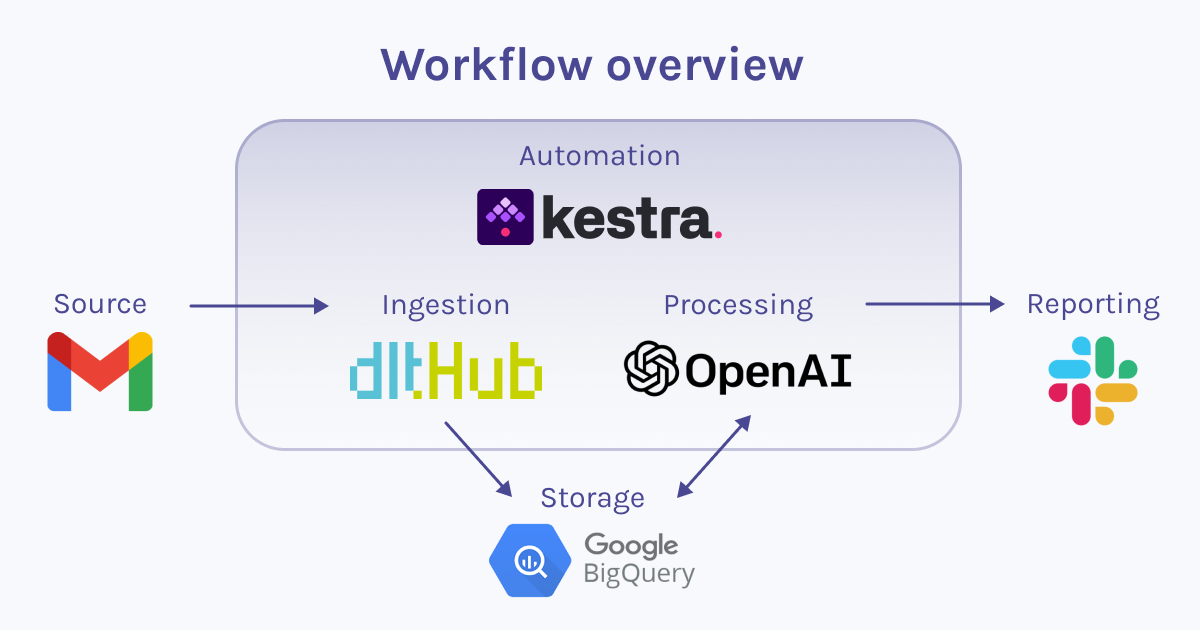
Now, let's delve into specific parts of the implementation.
The environment:
💡 The two flows in Kestra are set up in a very straightforward and intuitive manner. Simply follow the Prerequisites and Setup guidelines in the repo. It should take no more than 15 minutes.
Once you’ve opened http://localhost:8080/ in your browser, this is what you’ll see on your screen:
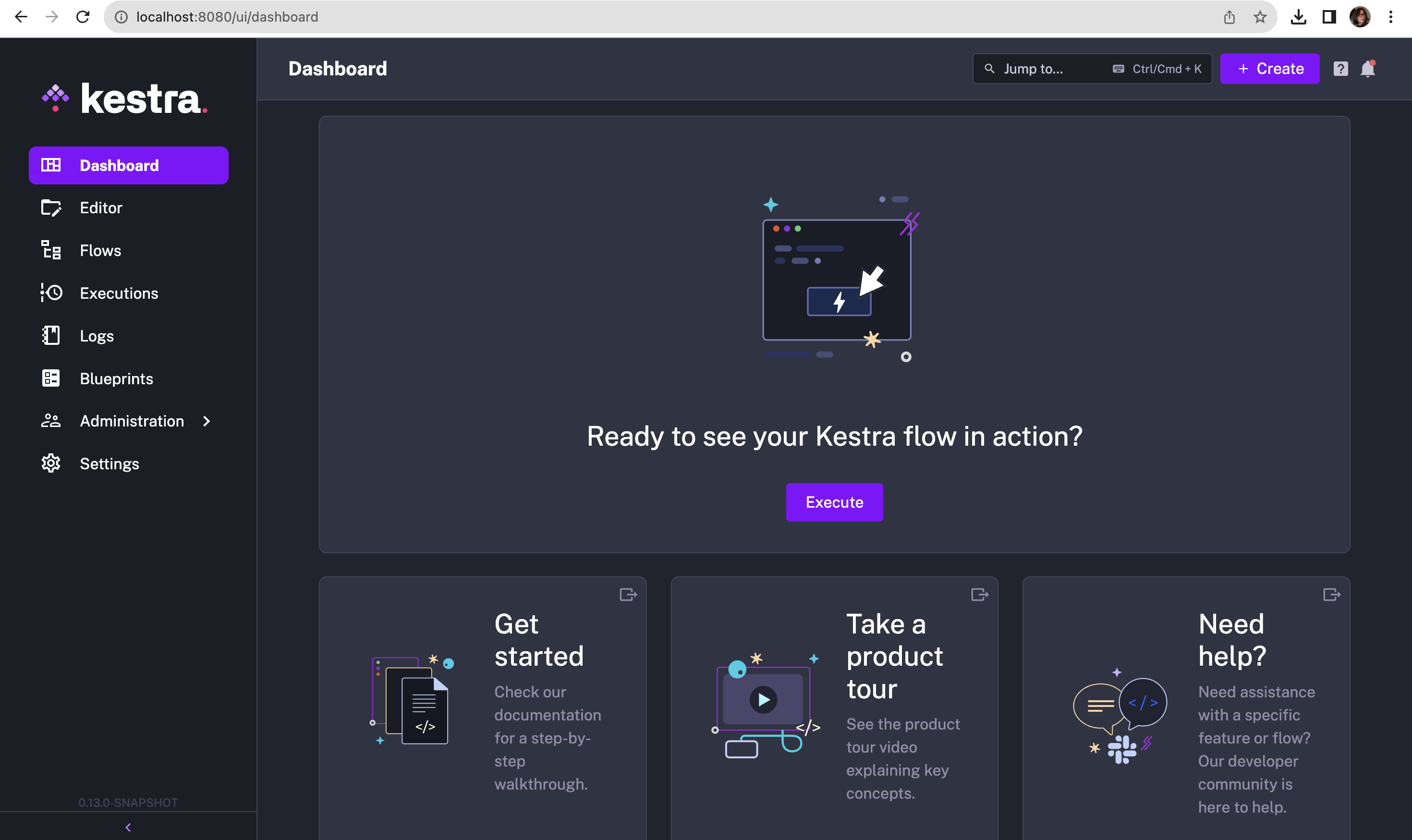
Now, all you need to do is create your flows and execute them.
The great thing about Kestra is its ease of use - it's UI-based, declarative, and language-agnostic. Unless you're using a task like a Python script, you don't even need to know how to code.
If you're already considering ways to use Kestra for your projects, consult their documentation and the plugin pages for further insights.
The data loading part
💡 This is entirely managed by
dltin just five lines of code.
I set up a pipeline using the Inbox source – a regularly tested and verified source from dlt – with BigQuery as the destination.
In my scenario, the email data doesn't have nested structures, so there's no need for flattening. However, if you encounter nested structures in a different use case, dlt can automatically normalize them during loading.
Here's how the pipeline is defined and subsequently run in the first task of the main flow in Kestra:
# Run dlt pipeline to load email data from gmail to BigQuery
pipeline = dlt.pipeline(
pipeline_name="standard_inbox",
destination='bigquery',
dataset_name="messages_data",
full_refresh=False,
)
# Set table name
table_name = "my_inbox"
# Get messages resource from the source
messages = inbox_source(start_date = pendulum.datetime(2023, 11, 15)).messages
# Configure the messages resource to get bodies of the emails
messages = messages(include_body=True).with_name(table_name)
# Load data to the "my_inbox" table
load_info = pipeline.run(messages)
In this setup ☝️, dlt loads all email data into the table “my_inbox”, with the email body specifically stored in the “body” column. After executing your flow in Kestra, the table in BigQuery should appear as shown below:
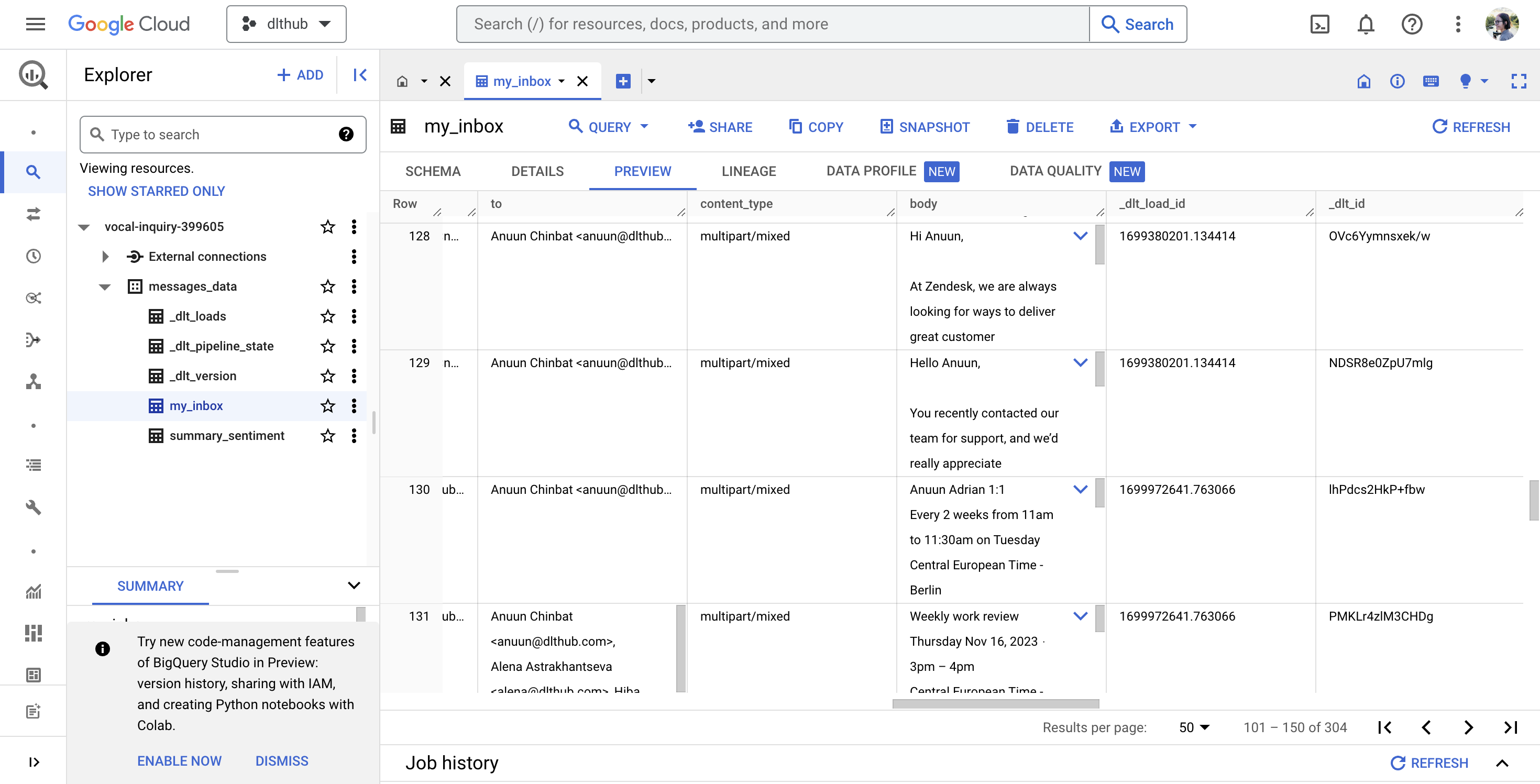
This implementation doesn't handle email attachments, but if you need to analyze, for instance, invoice PDFs from your inbox, you can read about how to automate this with dlt here.
The AI part
💡 In this day and age, how can we not incorporate AI into everything? 😆
But seriously, if you're familiar with OpenAI, it's a matter of an API call to the chat completion endpoint. What simplifies it even further is Kestra’s OpenAI plugin.
In my subflow, I used it to obtain both the summary and sentiment analysis of each email body. Here's a glimpse of how it's implemented:
- id: get_summary
type: io.kestra.plugin.openai.ChatCompletion
apiKey: "{{ secret('OPENAI_API') }}"
model: gpt-3.5-turbo
prompt: "Summarize the email content in one sentence with less than 30 words: {{inputs.data[0]['body']}}"
messages: [{"role": "system", "content": "You are a tool that summarizes emails."}]
Kestra also includes Slack, as well as BigQuery plugins, which I used in my flows. Additionally, there is a wide variety of other plugins available.
The automation part
💡
Kestratriggers are the ideal solution!
I’ve used a schedule trigger that allows you to execute your flow on a regular cadence e.g. using a CRON expression:
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "0 9-18 * * 1-5"
This configuration ensures that your flows are executed hourly on workdays from 9 AM to 6 PM.
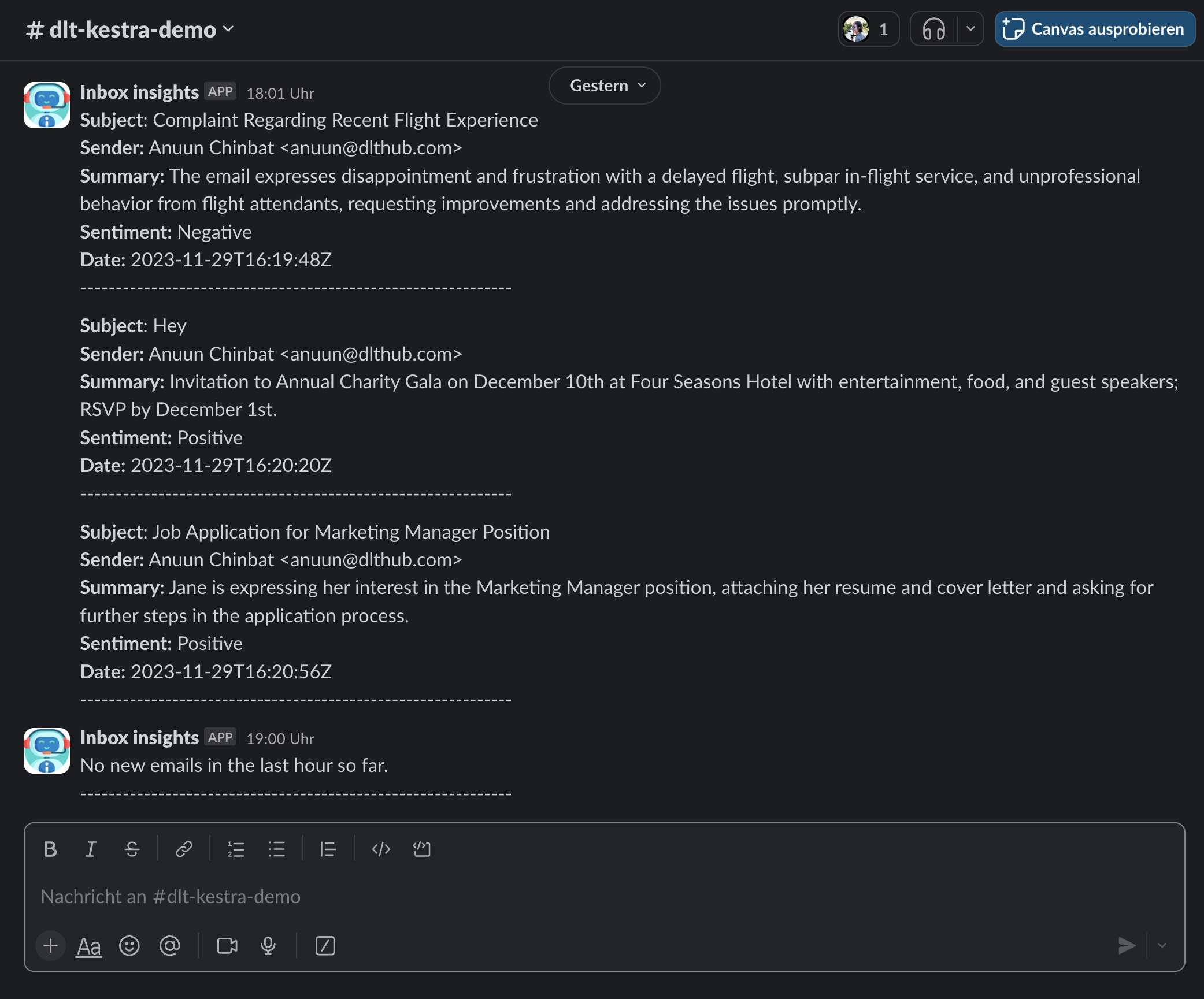
THE OUTCOME
A Slack assistant that delivers crisp inbox insights right at your fingertips:
And a well-organized table in BigQuery, ready for you to dive into a more complex analysis:
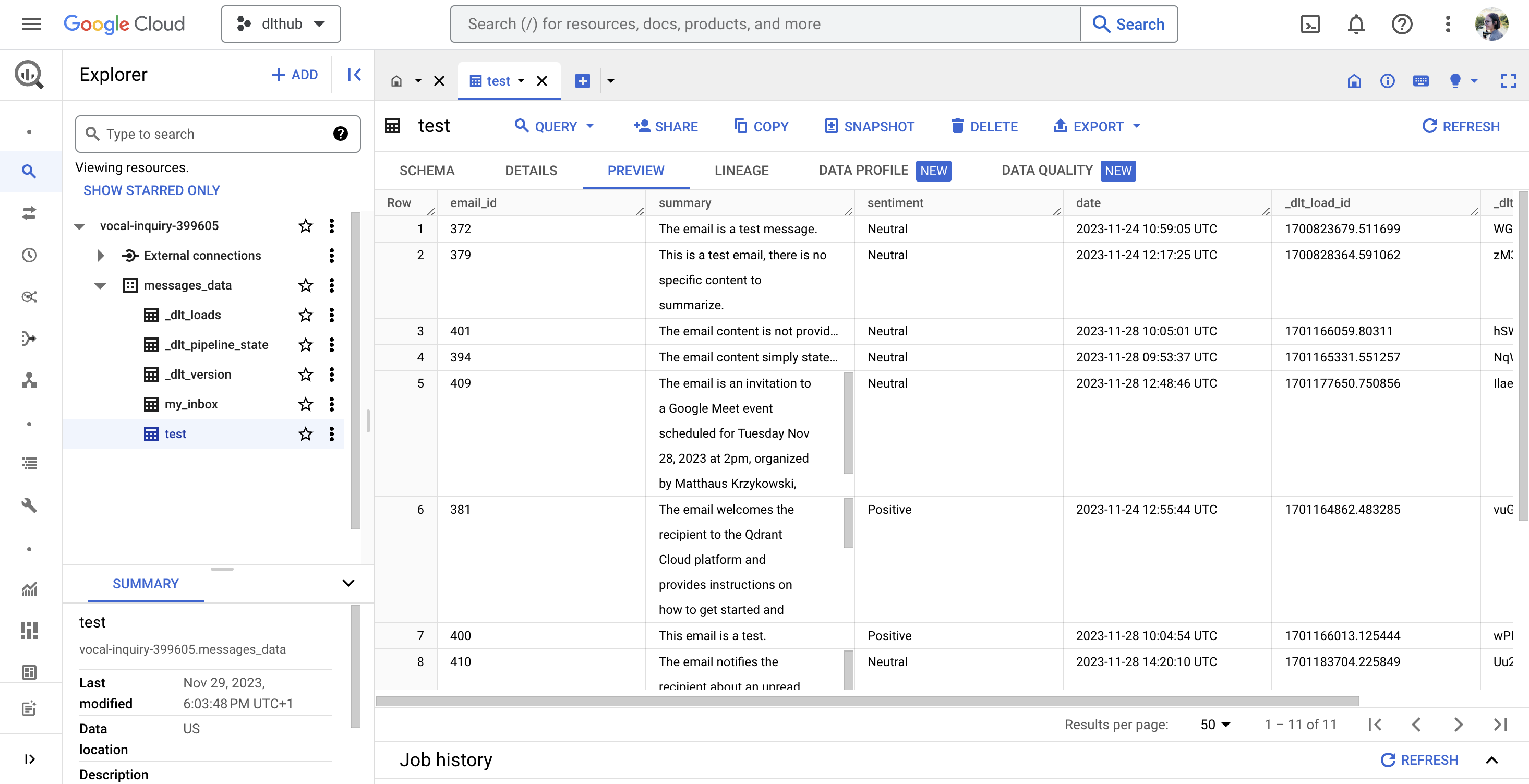
In essence, using Kestra and dlt offers a trio of advantages for refining email analysis and data workflows:
- Efficient automation:
Kestraeffortlessly orchestrates intricate workflows, integrating smoothly with tools likedlt, OpenAI, and BigQuery. This process reduces manual intervention while eliminating errors, and freeing up more time for you. - User-friendly and versatile: Both
Kestraanddltare crafted for ease of use, accommodating a range of skill levels. Their adaptability extends to various use cases. - Seamless scaling:
Kestra, powered by Kafka and Elasticsearch, adeptly manages large-scale data and complex workflows. Coupled withdlt's solid data integration capabilities, it ensures a stable and reliable solution for diverse requirements.
HOW IT COULD WORK ELSEWHERE
Basically, you can apply the architecture discussed in this post whenever you need to automate a business process!
For detailed examples of how Kestra can be utilized in various business environments, you can explore Kestra's use cases.
Embrace automation, where the only limit is your imagination! 😛