
TL;DR: Trying to become more user-centric and make data driven decisions? Get started with the SQL source pipeline + BigQuery + Metabase
When you have a web and / or mobile app but no data yet
If you're a startup without a dedicated data team but a sizeable number of users on your website or mobile app, then chances are that you are collecting and storing all your product data in OLTP databases like MySQL, Postgres, etc. As you have grown, you have likely been aiming to become more user-centric, yet you find that no one at your company has information on what your users do or what their experience is like. Stakeholders should be making data-driven decisions, but they are not yet because they are unable to use the existing data to understand user behavior and experience. This is usually the point when folks realize they need a data warehouse.
Why a data warehouse is necessary
OLTP databases are great because they are optimized to handle high-volume real-time transactions and maintain data integrity and consistency. However, they are not very well-suited for advanced analytics and data modelling. If you want to create reports, dashboards, and more that help you understand you users, you are going to want to extract, load, and transform (ELT) into a OLAP database like Google BigQuery, Snowflake, etc. To do this, you will need to create a data pipeline, which can be quite challenging if your company does not have a dedicated data engineering team.
Why a data pipeline is necessary
Production dashboards rely on the availability of consistent, structured data, which necessitates deploying a data pipeline that is idompotent, can manage the schema and handle schema changes, can be deployed to load data incrementally, etc. For most startups, it's not obvious how to create such pipelines. This is why we decided to demonstrate how one can set up such a data pipeline and build analytics dashboards on top of it.
Why a reporting tool is necessary
We chose to build our dashboard in Metabase because it also offers an open source edition. The advantage of reporting tools like Metabase is that they are easy and intuitive to use even for people who can't write SQL, but at the same time they are powerful enough for those who would like to use SQL.
How we set this up
1. Creating a PostgreSQL -> BigQuery pipeline
Our aim was to create a Metabase dashboard to explore data in a transactional database. The data set that we chose was a sample of The Dell DVD Store 2 database, which we put into a Postgres database deployed on a Google Cloud SQL instance. To make this data available to Metabase, we needed to first load all of the data into a BigQuery instance, and for this we needed a data pipeline. We created this pipeline by doing very simple customizations on the existing dlt sql_database pipeline. See the accompanying repo for the steps we followed.
2. Building a Metabase reporting dashboard
With the database uploaded to BigQuery, we were now ready to build a dashboard. We created a Metabase cloud account and connected it to our BigQuery instance. This made the whole database accessible to Metabase and we were able to analyze the data.
The DVD store database contains data on the products (film DVDs), product categories, existing inventory, customers, orders, order histories etc. For the purpose of the dashboard, we decided to explore the question: How many orders are being placed each month and which films and film categories are the highest selling?
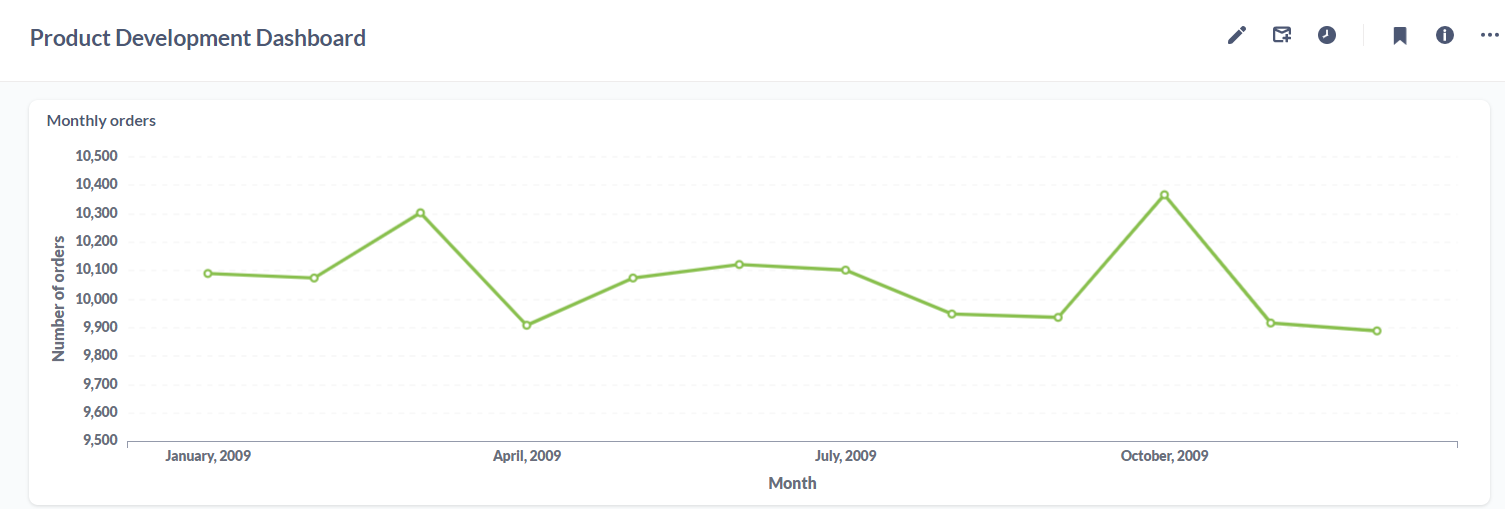
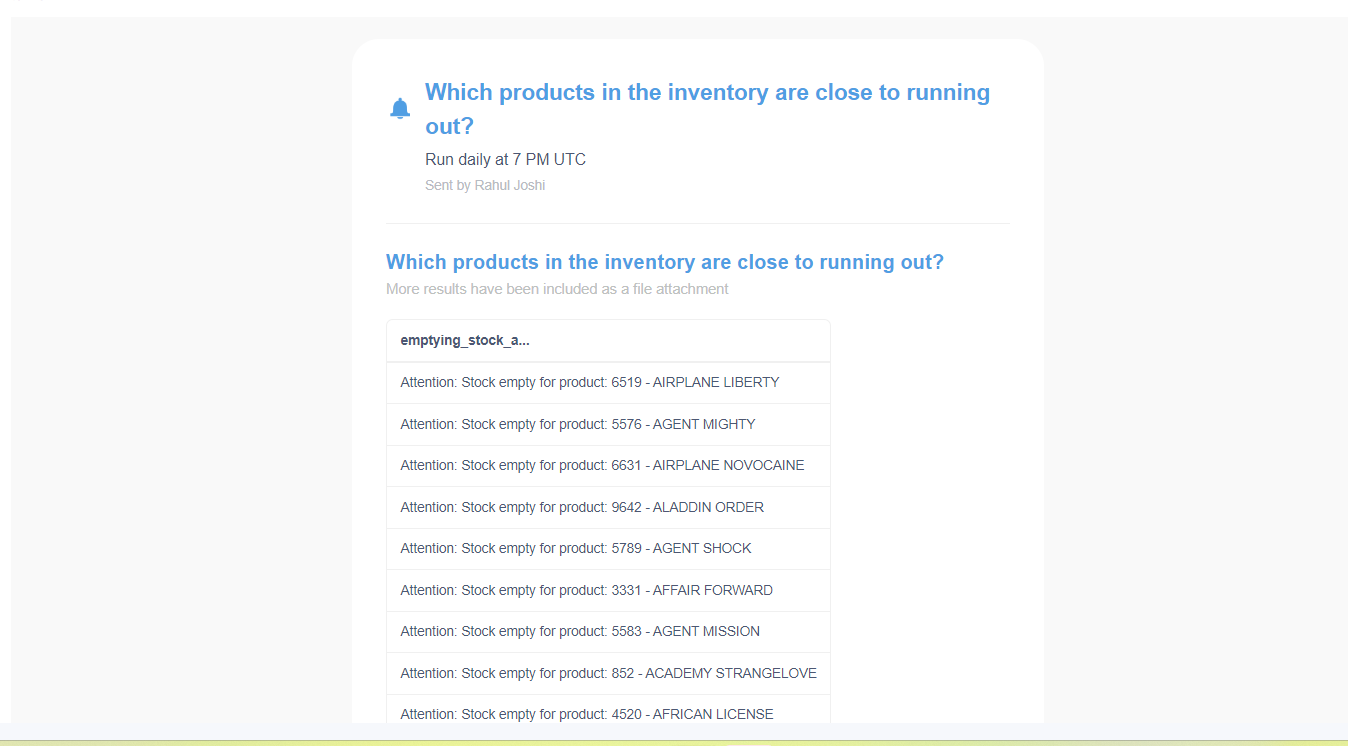
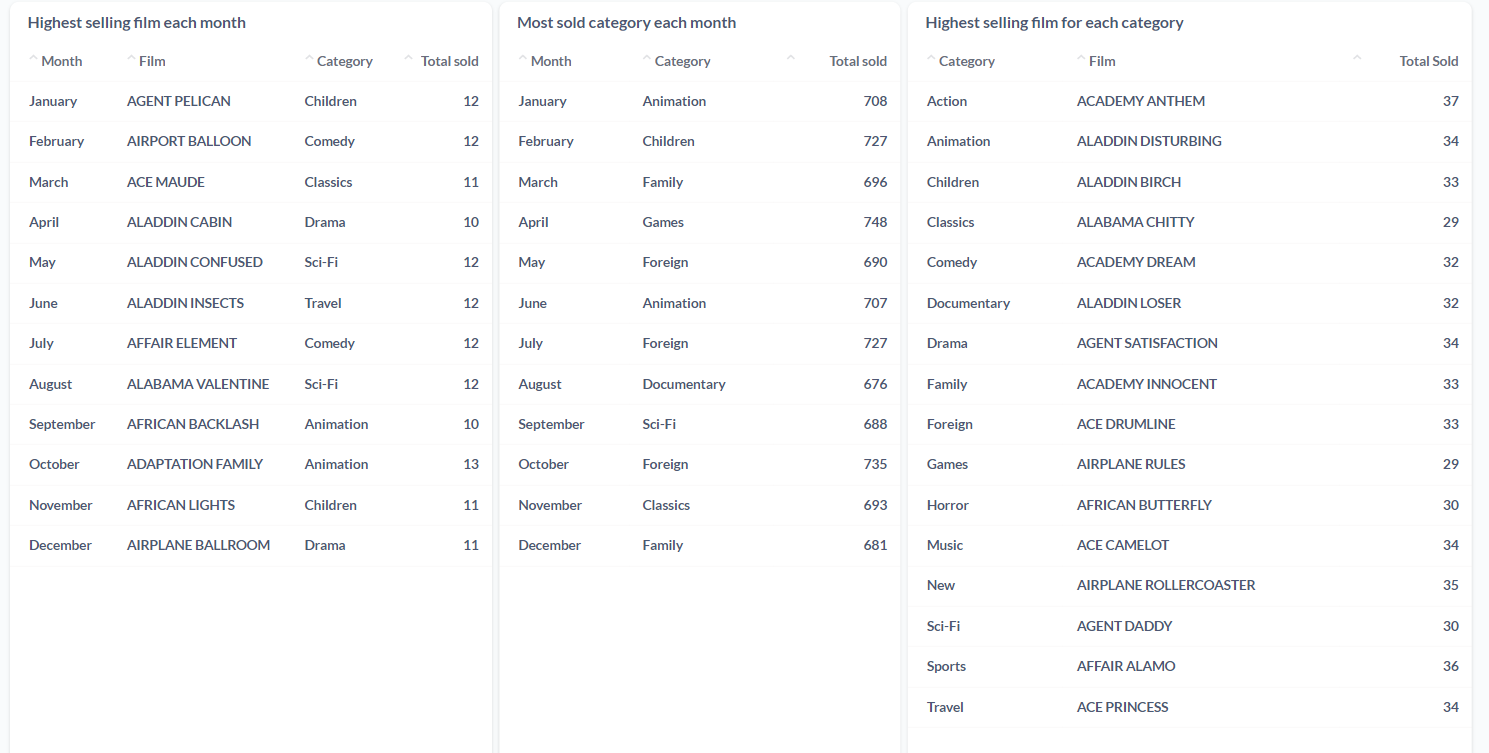 In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.
In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.
3. Deploying the pipeline
With our dashboard ready, all we had to do was deploy our pipeline so that the dashboard could get updated with new data daily. Since the dashboard only uses some of the tables, we needed to modify the pipeline, that was configured to load the entire database, to instead only update the necessary tables. We also wanted to make it possible for the pipeline to load tables incrementally whenever possible.
We first started by selecting the tables that we wanted to update, namely: orders, orderlines, products, categories, inventory. We then decided whether we wanted to update the tables incrementally or with full replace:
- Tables orders and orderlines contain data on the orders placed. This means that they also contain a date column and hence are loaded incrementally every day.
- Tables products, categories, and inventory contain information on the existing products. These tables don't contain a date column and are updated whenever there is any change in inventory. Since the values of the existing data in the tables can change, these tables are not updated incrementally, but are instead fully loaded each time the pipeline is run.
In order to specify these conditions and deploy our pipeline in production, we followed these steps.
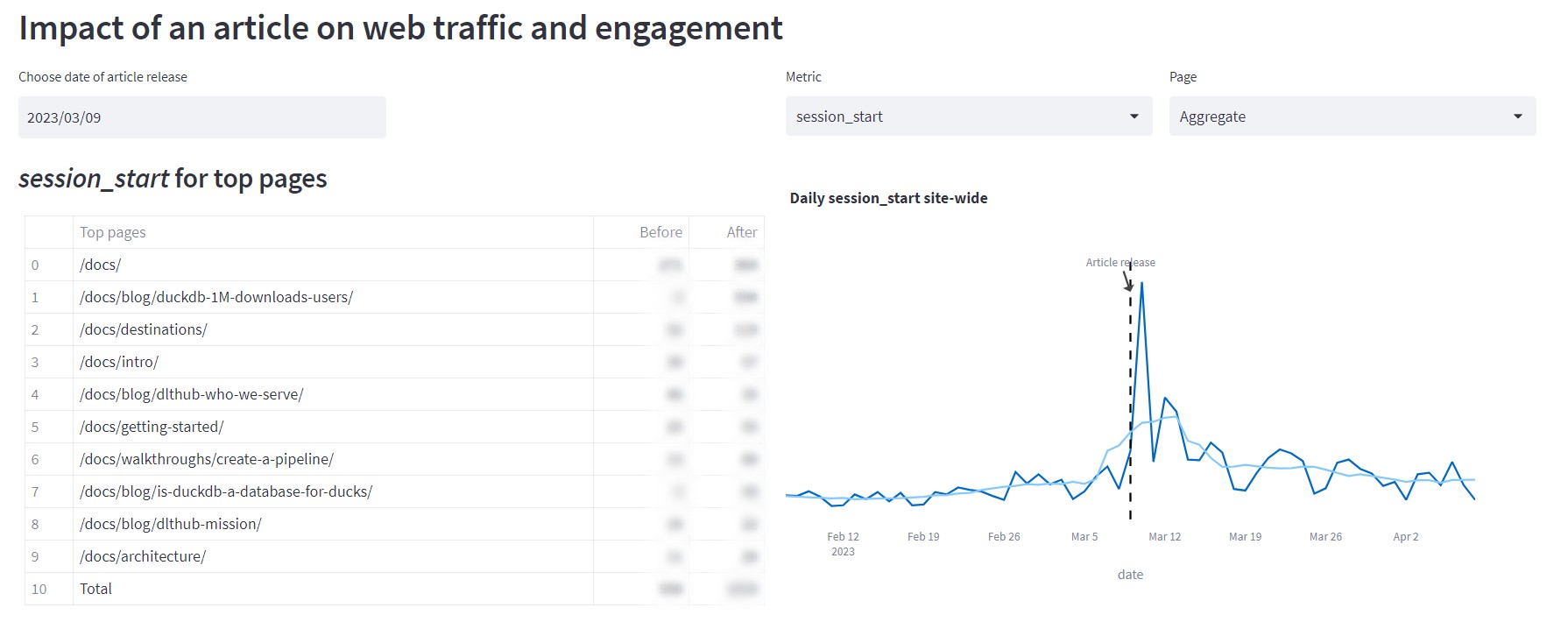
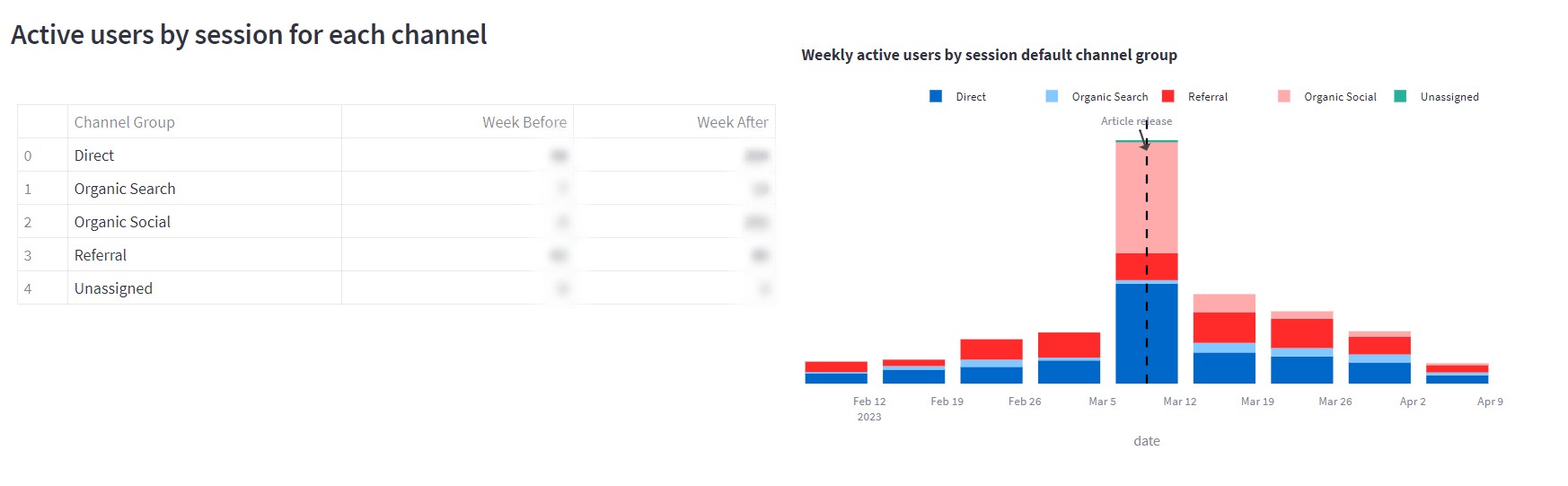

 Source:
Source: 