TL;DR: By linking each load's metadata to the schema evolution event or schema version, we are able to assign the origin of a column to a specific load package, identified by source and time.
Row and Column Level Lineage with dlt
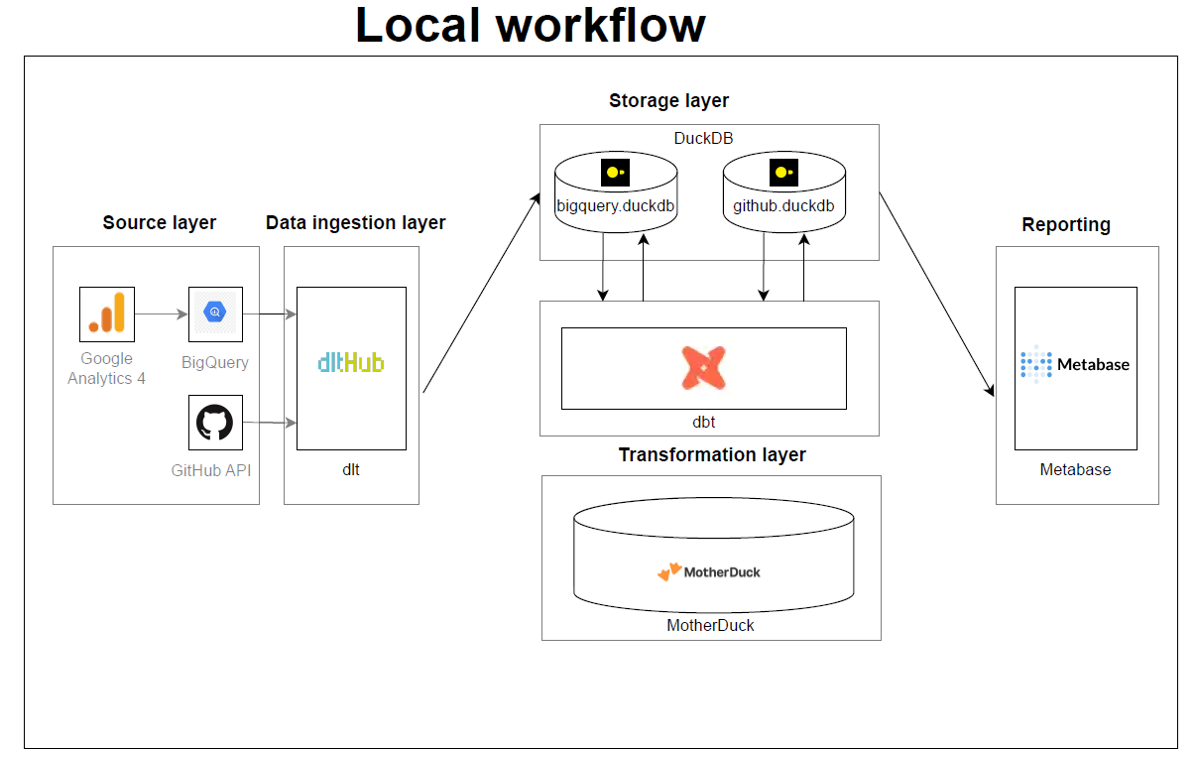
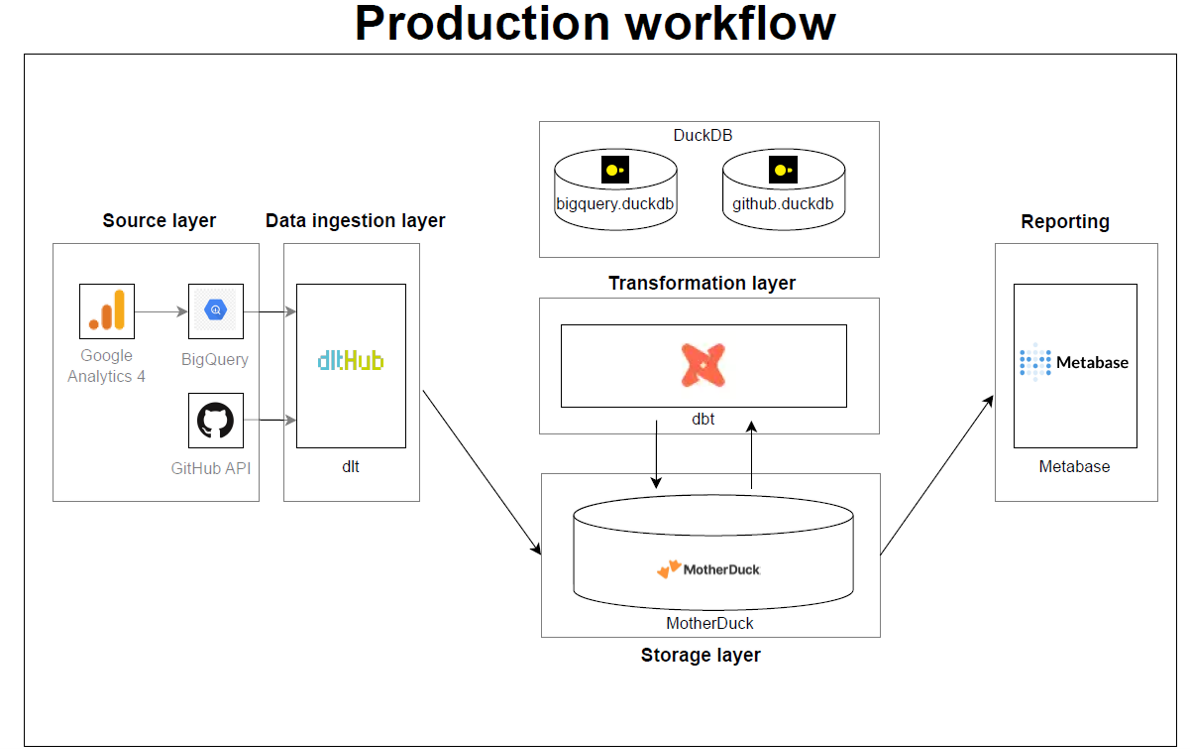
Load IDs
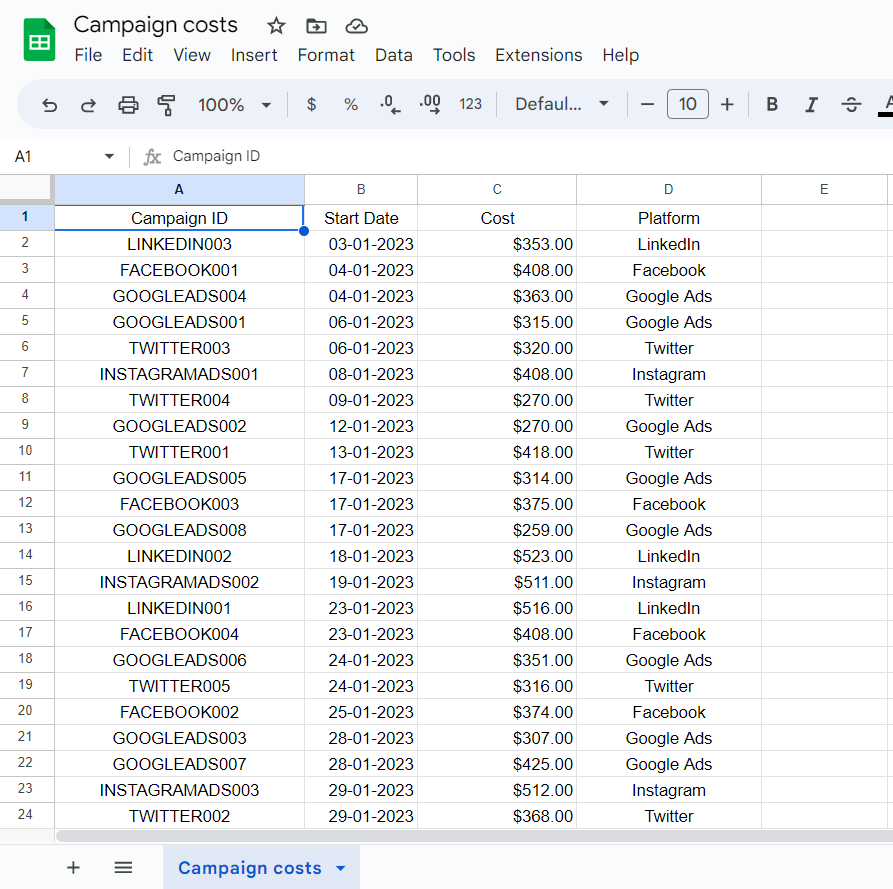
Load IDs are crucial in dlt and are present in all the top tables (_dlt_loads, load_id, etc.). Each pipeline run creates one or more load packages, which can be identified by their load_id. A load package typically contains data from all resources of a particular source. The load_id of a particular package is added to the top data tables and to the _dlt_loads table with a status 0 (when the load process is fully completed).
For more details, refer to the Load IDs section of the documentation.
Schema Versioning
Each schema file in dlt contains a content-based hash version_hash that is used to detect manual changes to the schema (i.e., user edits content) and to detect if the destination database schema is synchronized with the file schema. Each time the schema is saved, the version hash is updated.
For more details, refer to the Schema content hash and version section of the documentation.
Data Lineage
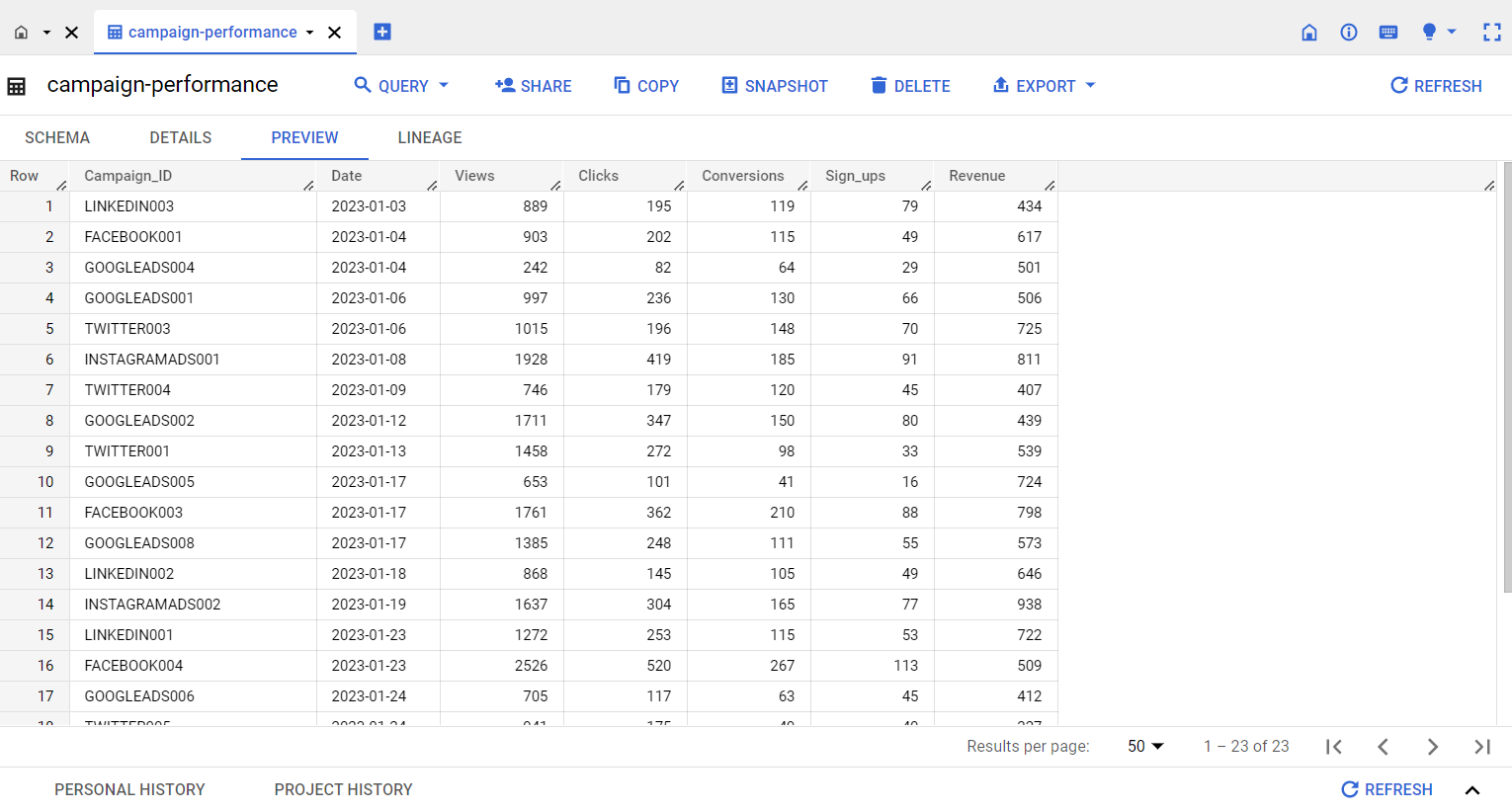
Data lineage can be super relevant for architectures like the data vault architecture or when troubleshooting. Using the pipeline name and load_id provided out of the box by dlt, you are able to identify the source and time of data.
You can save complete lineage info for a particular load_id including a list of loaded files, error messages (if any), elapsed times, schema changes. This can be helpful, for example, when troubleshooting problems.
For more details, refer to the Data lineage section of the documentation.
By combining the use of load_id and schema versioning, you can achieve a robust system for row and column level lineage in your data pipelines with dlt.
Row and Column Level Lineage
Row Level Lineage
Row level lineage refers to the ability to track data from its source to its destination on a row-by-row basis. This means being able to identify exactly where each row of data in your destination came from, which can be crucial for data validation, debugging, and compliance purposes.
In dlt, each row in all (top level and child) data tables created by dlt contains a unique column named _dlt_id. Each child table contains a foreign key column _dlt_parent_id linking to a particular row (_dlt_id) of a parent table. This allows you to trace the lineage of each row back to its source.
For more details, refer to the Child and parent tables section of the documentation.
Column Level Lineage
Column level lineage refers to the ability to track how each column in your data has been transformed or manipulated from source to destination. This can be important for understanding how your data has been processed, ensuring data integrity, and validating data transformations.
In dlt, a column schema contains properties such as name, description, data_type, and is_variant, which provide information about the column and its transformations. The is_variant property, for example, tells you if a column was generated as a variant of another column.
For more details, refer to the Tables and columns section of the documentation.
By combining row and column level lineage, you can have an easy overview of where your data is coming from and when changes in its structure occur.
Identifying the lineage with dlt
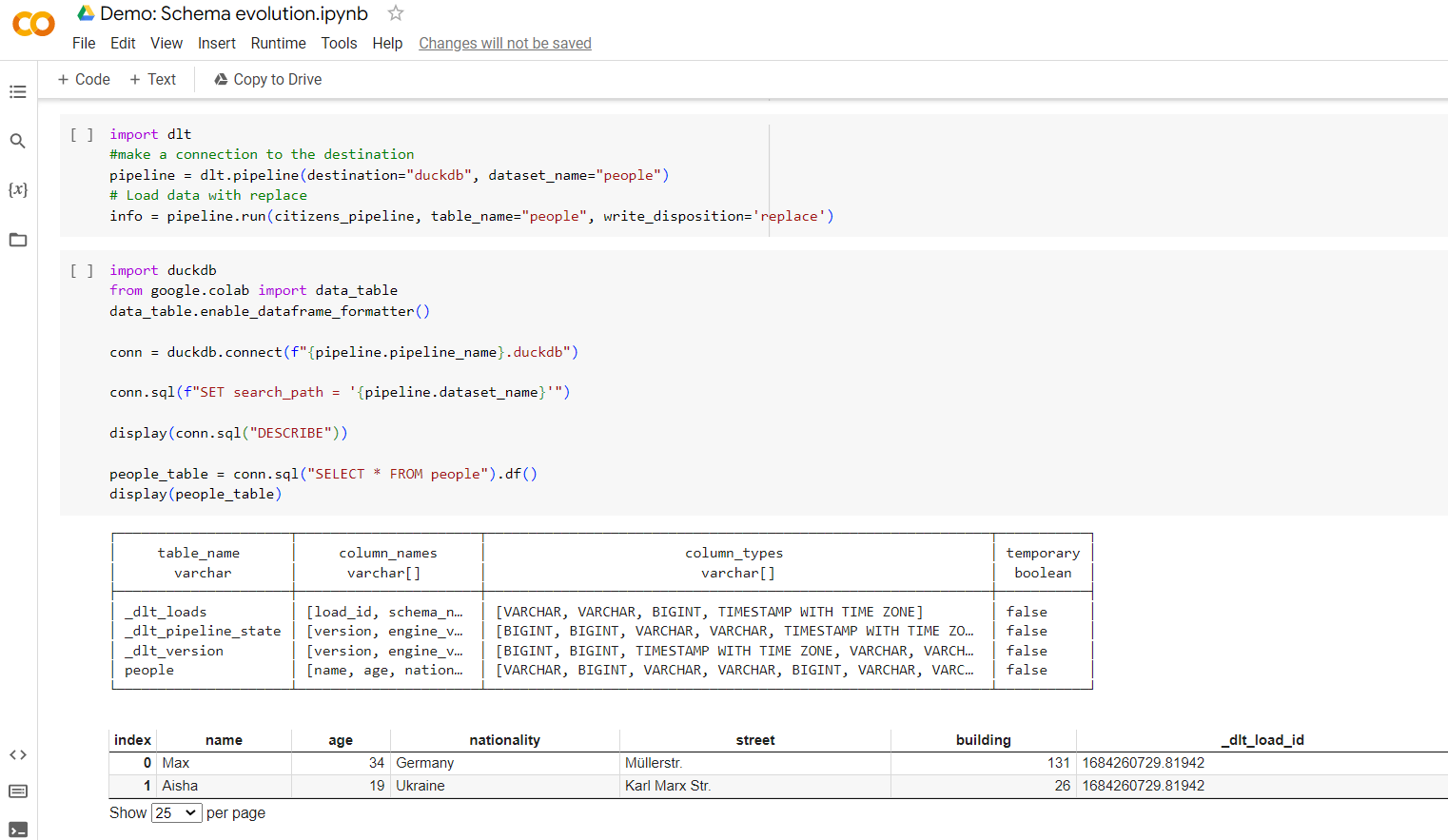
After a pipeline run, the schema evolution info gets stored in the load info. Load it back to the database to persist the column lineage:
load_info = pipeline.run(data,
write_disposition="append",
table_name="users")
pipeline.run([load_info], write_disposition="append", table_name="loading_status")
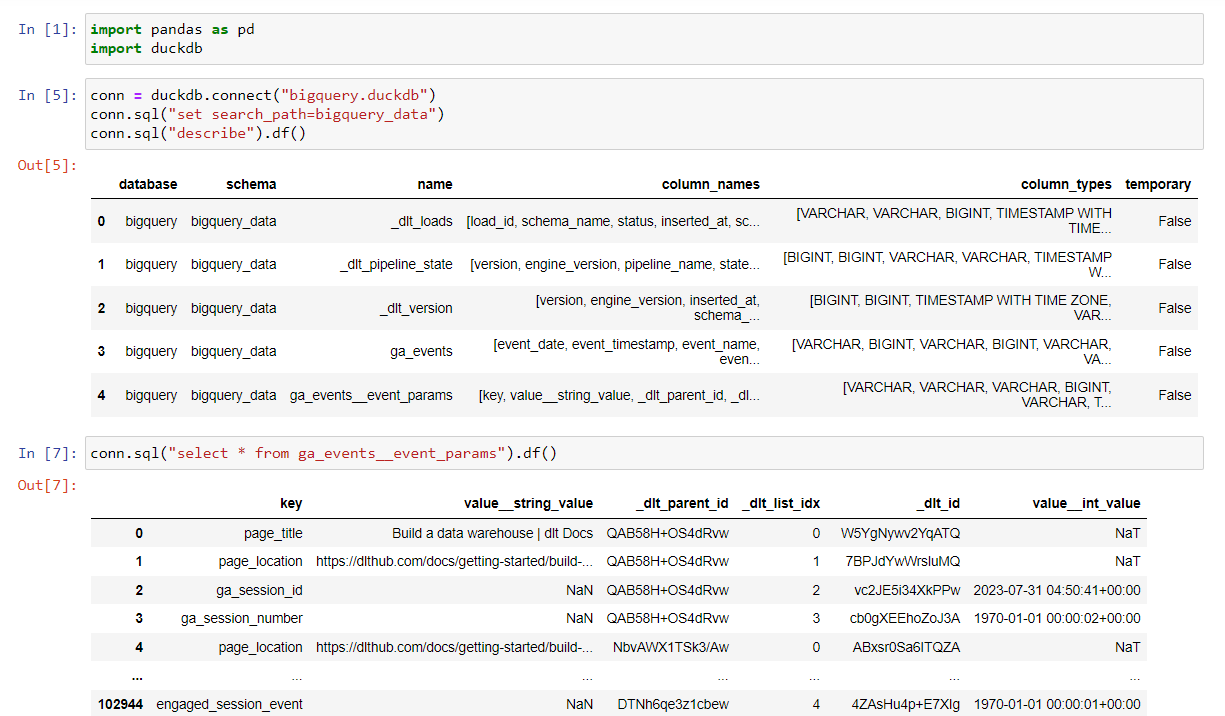
Loading it back to the database will produce a few status tables.
Note the load id, which is a unix timestamp, identifying the origin of every new column. You can link it back to the load packages via the _load_id column.
Below, you can find some examples of what this info looks like - Note the _load_id column that identifies each load, and the metadata that comes with it:
Here is an example what load info contains in the column info of the metadata we just loaded (table load_info__load_packages__tables__columns):
| nullable | partition | cluster | unique | sort | primary_key | foreign_key | root_key | merge_key | name | data_type | table_name | schema_name | load_id | _dlt_parent_id | _dlt_list_idx | _dlt_id | variant |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| false | false | false | false | false | false | false | false | false | version | bigint | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 0 | 4rQWa44uF2CKyg | |
| false | false | false | false | false | false | false | false | false | engine_version | bigint | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 1 | zn5zR+PKyNqJLA | |
| false | false | false | false | false | false | false | false | false | pipeline_name | text | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 2 | WV6DNovz7V1xBg | |
| false | false | false | false | false | false | false | false | false | state | text | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 3 | 77zsRk9Z5yhAwQ | |
| false | false | false | false | false | false | false | false | false | created_at | timestamp | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 4 | Sj5/mL9tZGlHRQ | |
| false | false | false | false | false | false | false | false | false | _dlt_load_id | text | _dlt_pipeline_state | dlt_test_pipe | 1692188651.466199 | WBS2MJRkxEn2xw | 5 | lvbvQFPbk9g0og | |
| false | false | false | false | false | false | false | false | false | load_id | text | _dlt_loads | dlt_test_pipe | 1692188651.466199 | G0HvoQ6BMNzYsw | 0 | +IeGJE0Ln0wj+w | |
| true | false | false | false | false | false | false | false | false | schema_name | text | _dlt_loads | dlt_test_pipe | 1692188651.466199 | G0HvoQ6BMNzYsw | 1 | oZ7hho/aLYJobg | |
| false | false | false | false | false | false | false | false | false | status | bigint | _dlt_loads | dlt_test_pipe | 1692188651.466199 | G0HvoQ6BMNzYsw | 2 | QrZ3e79agHFNgg | |
| false | false | false | false | false | false | false | false | false | inserted_at | timestamp | _dlt_loads | dlt_test_pipe | 1692188651.466199 | G0HvoQ6BMNzYsw | 3 | gm9kEFQuPXGwiA | |
| true | false | false | false | false | false | false | false | false | schema_version_hash | text | _dlt_loads | dlt_test_pipe | 1692188651.466199 | G0HvoQ6BMNzYsw | 4 | 4eX9BoFV5oegAg | |
| true | false | false | false | false | false | false | false | false | name | text | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 0 | ISj8XUllnHB1gA | |
| true | false | false | false | false | false | false | false | false | age | bigint | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 1 | 4YDwm8PtjtEPwA | |
| true | false | false | false | false | false | false | false | false | nationality | text | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 2 | LJTMxFWgqqyH/w | |
| true | false | false | false | false | false | false | false | false | street | text | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 3 | AmzkMpDFikafIw | |
| true | false | false | false | false | false | false | false | false | building | bigint | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 4 | GNw+E3FAuC9o5A | |
| false | false | false | false | false | false | false | false | false | _dlt_load_id | text | people | dlt_test_pipe | 1692188651.466199 | q9DzfCYuMwDjkg | 5 | 7hhoAuL9tZGlHR |
Here is the information contained in the load_info table:
| pipeline__pipeline_name | destination_name | destination_displayable_credentials | destination_fingerprint | dataset_name | started_at | first_run | _dlt_load_id | _dlt_id |
|---|---|---|---|---|---|---|---|---|
| dlt_test_pipe | bigquery | dlthub-loader@dlthub-analytics.iam.gserviceaccount.com@dlthub-analytics | kgecbRsVn7pCkgx5EVBi | people | 2023-08-16 12:24:09.511922 UTC | true | 1692188672.110346 | PP1cT3rrwur2pw |
| dlt_test_pipe | bigquery | dlthub-loader@dlthub-analytics.iam.gserviceaccount.com@dlthub-analytics | kgecbRsVn7pCkgx5EVBi | people | 2023-08-16 12:25:12.789753 UTC | false | 1692188728.938733 | WcBNyAKI3NdVzg |
Conclusion
In conclusion, implementing row and column level lineage within data processing is crucial for maintaining data integrity, validation, and troubleshooting. The dlt framework offers a robust solution for achieving both forms of lineage, providing a comprehensive understanding of data transformations and origins.
Row level lineage: Utilizing unique identifiers like
_dlt_idand_dlt_parent_id,dltenables precise tracing of data from source to destination. This level of detail is essential for tasks like data validation, debugging, and compliance.Column level lineage: By leveraging column schema properties such as name, data type, and
is_variant,dltreveals column transformations, offering insights into data manipulation throughout the pipeline.Extend lineage into transformation: To maintain dlt lineage into transformations, log metadata at each transformation step, including transformation type, logic, and timestamps, while extending lineage columns to represent transformed data's lineage and relationships.
Combining row and column level lineage provides data professionals with a holistic view of data's journey, enhancing comprehension of its source, transformations, and changes. The lineage information stored in dlt facilitates effective troubleshooting, validation, and compliance checks, bolstering governance of data pipelines.
In summary, the integration of lineage through dlt empowers organizations to construct transparent and reliable data pipelines. This practice ensures data quality, cultivating a foundation for accurate and trustworthy data-driven decisions.
Start using dlt today
What are you waiting for?